The Coming Collapse of Large Language Models
You’ve probably wondered: AI content is everywhere these days, but LLMs pre-train on high quality human-generated content. Doesn’t that mean AI output will just get increasingly worse? There’s a name for that problem: Model Collapse. It sounds dramatic, and for a little while, it had many developers and tech folks genuinely sweating. But what is model collapse really, and why is everyone suddenly… way less worried about it?
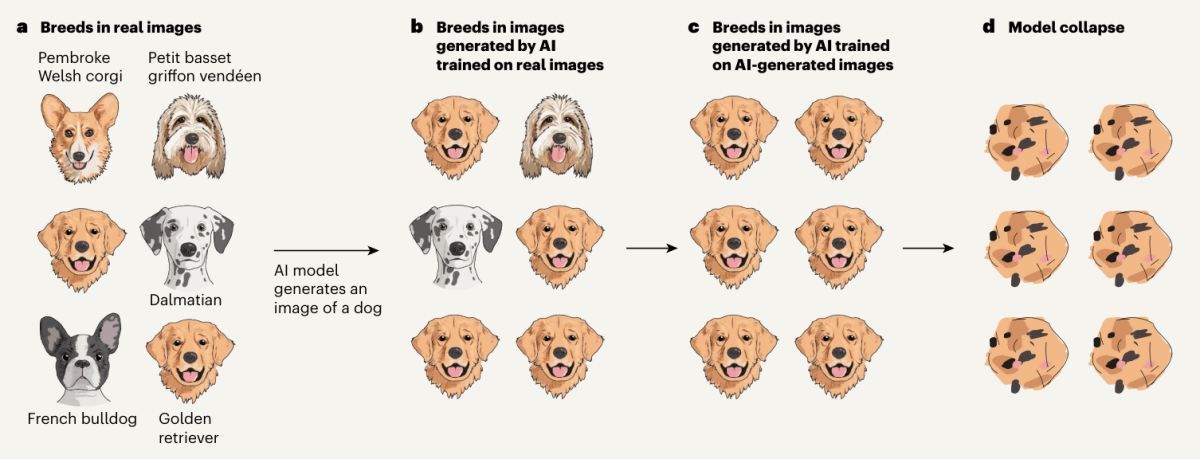
Let’s start simple: model collapse happens when language models start training more and more on data made by other models, instead of on real, human-created stuff. Imagine a world where you copy a copy of a copy, over and over. With every generation, some details fade away. In the world of LLMs, this means the subtle quirks, rare facts, and unique human touches start to disappear, and the model becomes bland, repetitive, or worse, starts spewing nonsense. Early studies gave researchers a scare by showing that, if this feedback loop goes unchecked, models could degrade fast. There were dire headlines about AIs “forgetting” how to write or think creatively, all because they kept learning from each other instead of real people’s words.
Cue the panic, right? For a while, yes. But as deeper studies rolled in and developers took a closer look, they realized the real situation wasn’t quite so bleak. The catastrophic scenarios in the early research tended to assume worst-case conditions, like models being trained only on synthetic content, with real human writing totally thrown out of the mix. But no major company actually trains LLMs this way, thankfully. In reality, most developers are incredibly careful to use big, diverse datasets, packed with genuine human text. The amount of human-made content out there is so massive that, as long as it’s part of the training diet, model collapse happens at a glacial pace.

Developers haven’t just relied on hope, though. They’re actively designing ways to spot and filter AI-generated content before it gets folded back into the pool. Think watermarking, smarter content filters, and all sorts of tech to keep training sets fresh and diverse. There are also ongoing efforts in the AI community to share best practices, track the quality of the data being used, and invest in data curation. That means people are continuously watching out for any early signs of “weirdness” or blandness creeping in, and taking action before things spiral.
At this point, most of the experts agree: model collapse is a real thing, but it’s not the looming apocalypse some headlines predicted. With the right strategies, it’s totally manageable. The big lesson? As long as developers keep mixing in plenty of authentic human-created language and pay close attention to their data hygiene, LLMs aren’t in any danger of forgetting how to be creative, insightful, and just a little bit weird—just like the humans they’re built to emulate.
Of course, there are opposing forces to human-generated content being used to train AI models. New York Times famously sued OpenAI for using their content, and the continuing revolt from creatives all over the world, exemplified by the SAG strikes of 2023, were partly caused by the threat of AI to Hollywood.